风险提示:本文内容旨在提供易读易懂的研报解读,不代表本站观点,也不构成任何投资建议。投资者看过本文后做出的任何投资决策与本站无关,市场有风险,投资需谨慎。
GPT大模型产业链股票纷纷大涨,市场的热点方向已经从“GPT+应用”扩展到垂直领域的大模型。众多计划推出基于自身领域的垂直类大模型的厂商中,近期彭博发布了拥有500亿参数的金融领域大模型,取名BloombergGPT。训练的数据集,51.3%来自于彭博近40年来的金融领域积累的数据,48.7%来自于公开数据。从最终的测试效果来看,在通用性能上,BloombergGPT相比其他模型没有明显的不足,但是在金融专业领域,BloombergGPT相比其他模型有明显的优势。而根据各特定领域模型的结果分析发现,通用模型并不能取代垂直领域的专门化需求,未来具备细分领域高质量数据的公司在大模型的应用上将获得先发优势。
一、BloombergGPT介绍
为BloombergGPT是基于开源的GPT-3框架进行扩展和改进的,利用了彭博社丰富的金融数据源,构建了一个3630亿个标签的数据集,支持金融行业内的各类任务。
1、数据集
BloombergGPT的数据集是由两部分组成的:一部分是来自彭博社自身的金融数据,另一部分是来自公开的通用数据。彭博社的金融数据包括以下几种类型:
– 新闻:包括彭博社自己出版的新闻和其他来源的新闻,涵盖了全球各地区和行业的各种话题;
– 分析报告:包括彭博社自己出版的分析报告和其他来源的分析报告,涵盖了股票、债券、商品、货币、基金等各种金融产品和市场;
– 交易数据:包括彭博社提供的实时和历史交易数据,涵盖了股票、债券、商品、货币、期权、期货等各种金融产品和市场;
– 公司数据:包括彭博社提供的公司相关信息,如财务报表、股东结构、管理层、业务范围等;
– 宏观经济数据:包括彭博社提供的宏观经济指标,如国内生产总值(GDP)、通货膨胀率、失业率、利率等。
这些数据都是经过清洗和标注的,以保证质量和一致性。彭博社的金融数据总共有3630亿个标签,占据了BloombergGPT数据集的51.3%。另一部分是来自公开的通用数据,主要包括维基百科、书籍语料库、社交媒体等筛选和去重后的数据,公开的通用数据总共有3450亿个标签,占据了BloombergGPT数据集的48.7%。
2、模型
BloombergGPT的模型是基于开源的GPT-3框架进行扩展和改进的。GPT-3是一种基于Transformer 的自回归语言模型,能够通过预训练和微调来适应不同的任务。GPT-3有多个版本,参数数量从1.3亿到1750亿不等,其中最大的版本是GPT-3 XL ,拥有1750亿个参数。BloombergGPT在GPT-3 XL的基础上,增加了模型层数、隐藏层大小、注意力头数等参数,使得模型参数数量达到了500亿,是目前已知的最大的金融领域LLM。BloombergGPT使用了相同的词表和编码方式,以及相同的优化器和学习率策略,与GPT-3 XL保持一致。BloombergGPT使用了混合精度训练 和梯度累积 等技术,以提高训练效率和稳定性。BloombergGPT使用了256个GPU进行训练,每个GPU有32GB的显存。BloombergGPT总共训练了100个epoch,每个epoch大约需要4天时间。BloombergGPT在训练过程中使用了动态数据采样 ,根据每个数据类型在整个数据集中的比例来调整其采样概率,从而保证数据集的平衡性。
3、评估
BloombergGPT在多个标准的LLM基准测试和开放的金融基准测试上进行了评估,并与其他现有的模型进行了比较。此外,BloombergGPT还在一系列内部开发的金融基准测试上进行了评估,以更好地反映其在实际应用中的效果。
– 标准LLM基准测试,包括语言建模(LM)、阅读理解(RC)、命名实体识别(NER)、关系抽取(RE)、文本分类(TC)、文本生成(TG)。BloombergGPT在这些任务上的准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值(F1 Score)等指标上都超过了其他模型,尤其是在NER和RE这两个与金融领域密切相关的任务上优势更加明显。这说明BloombergGPT能够在通用领域的各种任务上表现出良好的泛化能力,同时也能够利用其金融领域的专业知识来提高效果。
– 开放的金融基准测试,主要包括金融问答(FQA)、金融情感分析(FSA)、金融摘要生成(FSG)、金融新闻生成(FNG)。BloombergGPT在所有的开放的金融基准测试上同样超过了其他模型,尤其是在FQA和FNG这两个与金融领域密切相关的任务上,BloombergGPT的优势更加明显。这说明BloombergGPT能够在金融领域的各种任务上表现出卓越的专业能力,同时也能够利用其通用领域的知识来提高效果。
– 内部的金融基准测试,主要包括金融知识图谱(FKG)、金融对话系统(FDS)、金融预测(FP)、金融推荐(FR)。BloombergGPT在所有的内部的金融基准测试上都表现出了较高的水平,尤其是在金融知识图谱的表现非常出色。这说明BloombergGPT能够在彭博社自己开发的各种任务上表现出强大的专业能力,同时也能够利用其通用领域的知识来提高效果。
4、应用
BloombergGPT作为一个专门针对金融领域的LLM,有着广泛的应用场景和潜力。以下是一些可能的应用场景:
– 金融智能助理:BloombergGPT可以作为一个金融智能助理,为用户提供各种金融相关的服务,如查询信息、回答问题、生成报告、提供建议等;
– 金融内容生成:BloombergGPT可以作为一个金融内容生成器,为用户生成各种金融相关的内容,如新闻、摘要、评论、预测等;
– 金融知识获取:BloombergGPT可以作为一个金融知识获取器,为用户获取各种金融相关的知识,如知识图谱、关系网络、趋势分析等;
– 金融教育和培训:BloombergGPT可以作为一个金融教育和培训的工具,为用户提供各种金融相关的教育和培训,如课程、案例、测试等。
二、BloombergGPT的启示及概念龙头
金融行业拥有大量C端用户群体,积累了海量数据,应用场景丰富,是优质AI落地场景,目前在智能客服、无人柜台、智能投顾、反欺诈、自动业务批处理等金融场景,AI技术已广泛应用其中。具体来说:
– 智能投顾领域,生成式AI可以作为辅助信息融入推荐系统,生成数据分析和研究报告,提出个性化投资建议,可以提升信息利用率、增强推荐效果,目前已在部分金融信息服务商应用落地。
– 智能客服领域,Gartner认为85%的客户与企业交互无需人工参与,头部银行已走在前列,保险、证券也处于AI产品替代和辅助的升级中,GPT类预训练模型将AI对话提升至新的高度。
– 风控领域,生成式AI可以针对各类业务对象生成分析报告,提出个性化风控建议,如银行的风控、贷后,证券的两融等。
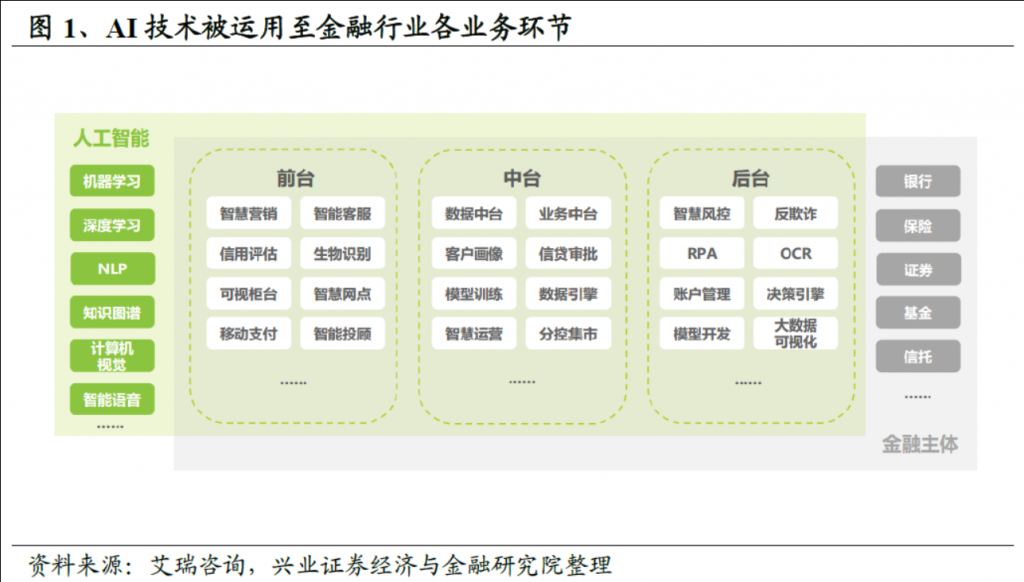
从BloombergGPT的研发、产出及应用领域来看,国内还没有成熟的金融大模型及应用,但在数据积累、模型研发有一定积累的公司在GPT类模型的研发和应用上更有优势:
- 同花顺。在数据资源、C端客群上有深厚积累,在AI领域积累多年,GPT类模型的研发将有极大提升如i问财、智能投顾、智能客服等AI服务能力。此外,公司构建AI开放平台,智能化解决方案已在多家银行、证券、基金等金融客户落地。
- 财富趋势。证券客户端已应用了部分AI能力。
- 东方财富。已研发金融数据AI智能化生产平台、多媒体智能资讯及互动平台系统等多个AI项目。
- 恒生电子。设立恒生研究院,持续部署包括AI在内的前沿技术,未来将积极探索生成式AI技术与金融核心业务场景的应用融合,在投研、投顾、营销、客服、运营、风控等金融各类业务场景开展人工智能大模型技术应用。
VCAI.CN 原创文章,转载请注明出处:https://vcai.cn/index.php/zhuti-20230403-aijinrong/